
最近は割とTVerで満足している部分はあるんだけど、とはいえ録画したいものがないわけでもないという理由でずっと維持していたfoltia ANIME LOCKERが電源やらHDDやら変えながら10年を軽く超えているな、ということで、さすがに置き換えを考えてみる。
CPUがCore i7-2600Sっていつのやつだっけ、というレベルのPCでQSVも使えないので、ソフトエンコードだしというあたりを改善したいところ。といっても、そんな数多く録画するわけでもなく、速度に不満があるわけでもない(大体、録画時間と同じくらいのエンコード速度であれば許せる)ので、なんとなく維持してきたけど、さすがに交換するために再構築するぞ、という感じ。
といいながら、実際のところは、2年ほど前に、一度、mirakcのtimeshift-fsで全録していたものを番組ごとに切りだしてAmatsukazeでエンコードする、というのを作っていてそれなりに動くところまでは作ったのだが、試しに動かしている途中でPCがクラッシュしてスクリプトを消失するという悲しい出来事があってまたしばらく放置していたのを気を取り直してやり直してる感じでもある。
前にやっていた全録から切り出すのも悪くはない気はしたけど、HDDの寿命とかも気になるし、まあ全部録るほどの理由も特に無かったなというので、あらためて要件をざっとあげる。
- たまに番組を個別録画したい
- キーワードで定期的に検索してマッチしたものを録画
- しょぼいカレンダーからアニメ新番組情報取得して録画したい
くらいかなとおもって、まずは普通に個別録画できるように環境を構築してみる。
しょぼいカレンダーとの連携はたぶん後回し(別ページ)にする気がする。
Rock 5B
とりあえず、チューナーを動かさないとはじまらないので手持ちにあるPX-S1UD x 5を動かしてみる。PX-Q3U4もどこかにあった気がするんだけど……見つからん。
mirakcを動かすPCをなにか用意しないとということでどうしようかと思ったが、今回は積んだままになっていたRock 5Bで動かす。rootfsを入れるメディアは、microSDでもいいんだけど、手元に1TBのNVMEがあったので、これにArmbianを入れてどうにかする。手順は公式ドキュメント通り。
https://docs.radxa.com/en/rock5/rock5b/getting-started/install-os/nvme
SPI Flash更新して、NVMEにArmbianのイメージをddで書いたら普通に立ち上がってきた。最近は本当に環境が整備されているなぁとなんか感動してしまった。
PX-S1UDのドライバ自体は、6.1とかであればそのまま動くようなので、ファームウェアだけ公式配布のzipからもってきて、/lib/firmwareに配置すると認識した。
[ 17.100581] smsdvb:smsdvb_hotplug: DVB interface registered.
[ 18.070077] dvbdev: DVB: registering new adapter (Siano Rio Digital Receiver)
[ 18.070136] dvbdev: dvb_create_media_entity: media entity 'dvb-demux' registered.
[ 18.070333] dvbdev: dvb_create_media_entity: media entity 'Siano Mobile Digital MDTV Receiver' registered.recisdb-rs
今まではrecdvbを動かしていた記憶だったんだけど、最近はrecpt1とかrecdvb相当で、Rust実装のrecisdb-rsというのがあるようだ。
b25とかの話も包含してくれそうだし亜種とかあってどれを使えばいいんだ……みたいなことにならない感じでいいなとおもったので、今回はこれを使ってみる。といっても、arm64向けにはパッケージがあるので、そのまま入れる。
$ wget https://github.com/kazuki0824/recisdb-rs/releases/download/1.2.2/recisdb_1.2.2-1_arm64.deb
$ sudo apt install ./recisdb_1.2.2-1_arm64.deb
$ rm ./recisdb_1.2.2-1_arm64.debちなみに、B-CASカードはpcscdを動かしていて、pcsc_scanで見えている状態にしていれば普通に読んでくれるようだ。
checksignalで45dBくらいで見えるので問題なさそうということで、オススメされていたISDBScannerでチャンネルスキャンして想定通りのチャンネルが検出されたことと、mirakc向けの設定が生成されることを確認して、一旦終了。
mirakc
このあたりまで動作確認したところで、あとはmirakcで制御したいので、Dockerで動かすように設定していく(なので、実際はDockerfileでrecisbdもインストールするようにするので、上記のホスト側に入れる意味はないと言えばない)
mirakcはできるmirakcにほぼ従う感じでOKだが、上記recisdb-rsを入れるためにカスタムイメージを作るのだけ先にやってあとはその通りに進めていく。
カスタムイメージの作成
といっても、パッケージがすでにあるものを入れるだけなので、シンプルにrecisdbをパッケージで追加するだけ。パッケージがdebが用意されているので、イメージのベースをalpineではなく、debianのものでapt installを追加実行するDockerfileを作る。
FROM mirakc/mirakc:main-debian
RUN apt-get update && apt-get install -y wget
RUN wget https://github.com/kazuki0824/recisdb-rs/releases/download/1.2.2/recisdb_1.2.2-1_arm64.deb
RUN apt install -y ./recisdb_1.2.2-1_arm64.deb
RUN rm ./recisdb_1.2.2-1_arm64.debICカードリーダのアクセスはrecisdbから直接行われるので、ホスト側でpcscdを動かしておいて、コンテナから通信できるように仕立てる形でvolumes経由でドメインソケットを触れるようにすればよいみたいなので、特に追加パッケージなどは要らなそう。
あとはビルドする。
$ sudo docker build -t custom/mirakc .この作業以外は、できるmirakcのままでOKで、compose.yamlとconfig.ymlを用意する。
services:
mirakc:
image: custom/mirakc
container_name: mirakc
init: true
restart: unless-stopped
ports:
- 40772:40772
privileged: true
devices:
- /dev/dvb/adapter0/frontend0
- /dev/dvb/adapter1/frontend0
- /dev/dvb/adapter2/frontend0
- /dev/dvb/adapter3/frontend0
- /dev/dvb/adapter4/frontend0
volumes:
- /var/run/pcscd/pcscd.comm:/var/run/pcscd/pcscd.comm
- mirakc-epg:/var/lib/mirakc/epg
- ./config.yml:/etc/mirakc/config.yml:ro
- /mnt/recorded/mirakc:/var/lib/mirakc/recording
- miraview-html:/var/www/miraview:ro
environment:
TZ: Asia/Tokyo
RUST_LOG: info
miraview:
image: docker.io/mirakc/mirakc:alpine
container_name: miraview-loader
restart: "no"
volumes:
- miraview-html:/var/www/miraview
working_dir: /var/www/miraview
environment:
MIRAVIEW_VERSION: v0.1.2
entrypoint: ash
command: -c "curl -L https://github.com/maeda577/miraview/releases/download/$$MIRAVIEW_VERSION/build.tar.gz | tar -zxvf -"
volumes:
mirakc-epg:
name: mirakc_epg
driver: local
miraview-html:
name: miraview_html
driver: local
取得できたEPGを確認する&後述するprogram IDをつかってCLIから予約をするためにmiraviewも同一コンテナ内にhtml+js+cssを入れて参照できるようにしておく。
config.yml内のtunersはISDBScannerで生成した設定をそのまま持ってくる(5個目のチューナーは番組延長などの追従専用にする)
server:
addrs:
- http: '0.0.0.0:40772'
mounts:
/miraview:
path: /var/www/miraview
index: index.html
epg:
cache-dir: /var/lib/mirakc/epg
recording:
records-dir: /var/lib/mirakc/recording/recorded
basedir: /var/lib/mirakc/recording
channels:
- name: NHKEテレ
type: GR
channel: T13
disabled: false
- name: NHK総合
type: GR
channel: T20
disabled: false
... 省略...
tuners:
- name: 'PLEX PX-S1UD / PX-Q1UD / VASTDTV VT20 #1'
types:
- GR
command: recisdb tune --device /dev/dvb/adapter0/frontend0 --channel {{{channel}}}
-
disabled: false
- name: 'PLEX PX-S1UD / PX-Q1UD / VASTDTV VT20 #2'
types:
- GR
command: recisdb tune --device /dev/dvb/adapter1/frontend0 --channel {{{channel}}}
-
disabled: false
- name: 'PLEX PX-S1UD / PX-Q1UD / VASTDTV VT20 #3'
types:
- GR
command: recisdb tune --device /dev/dvb/adapter2/frontend0 --channel {{{channel}}}
-
disabled: false
- name: 'PLEX PX-S1UD / PX-Q1UD / VASTDTV VT20 #4'
types:
- GR
command: recisdb tune --device /dev/dvb/adapter3/frontend0 --channel {{{channel}}}
-
disabled: false
- name: gr-tracker
types:
- GR
command: recisdb tune --device /dev/dvb/adapter4/frontend0 --channel {{{channel}}}
-
disabled: false
onair-program-trackers:
tracker:
local:
channel-types: [GR]
uses:
tuner: gr-trackerここまで用意すると、
$ docker compose upで起動して、特にエラーがなければOK。(実際の構築のときには、とりあえず、channelsとtunersを設定して、次はEPGキャッシュを有効にして、その後、録画を有効にする、といった形でできるmirakcにしたがって設定ごとに都度起動してエラーがないことを確認しながら構築するのがオススメ。)
とりあえずはバックグラウンドでの実行にはせず、screenなりでフォアグランドのままにしておく。
局ロゴなどにはあまり興味がないので、そのあたりは飛ばしてしまって、この状態で5-10分待つとEPGが取得できて、miraviewで番組表が見れることを確認する。
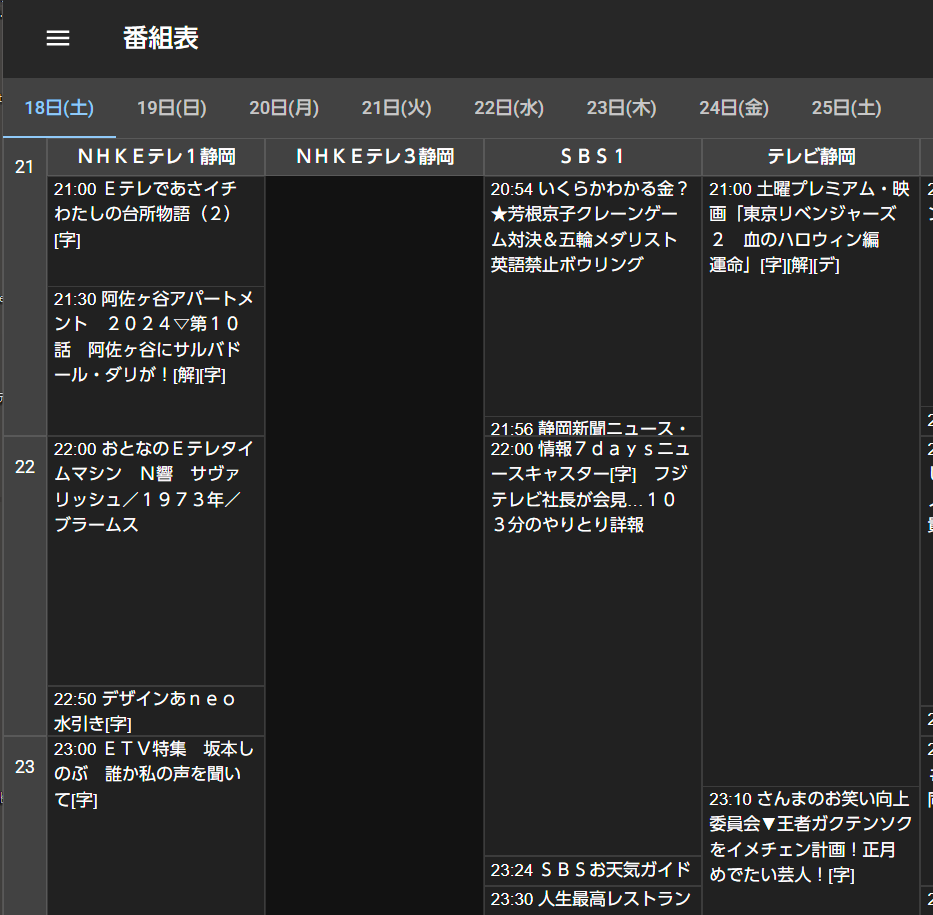
録画予約はとりあえずはmirakc/contribに用意されているコマンドで追加する形。EPGStationとか入れてもいいんだけど、そこまでヘビーに使うわけでもないんだよなということで一旦保留。
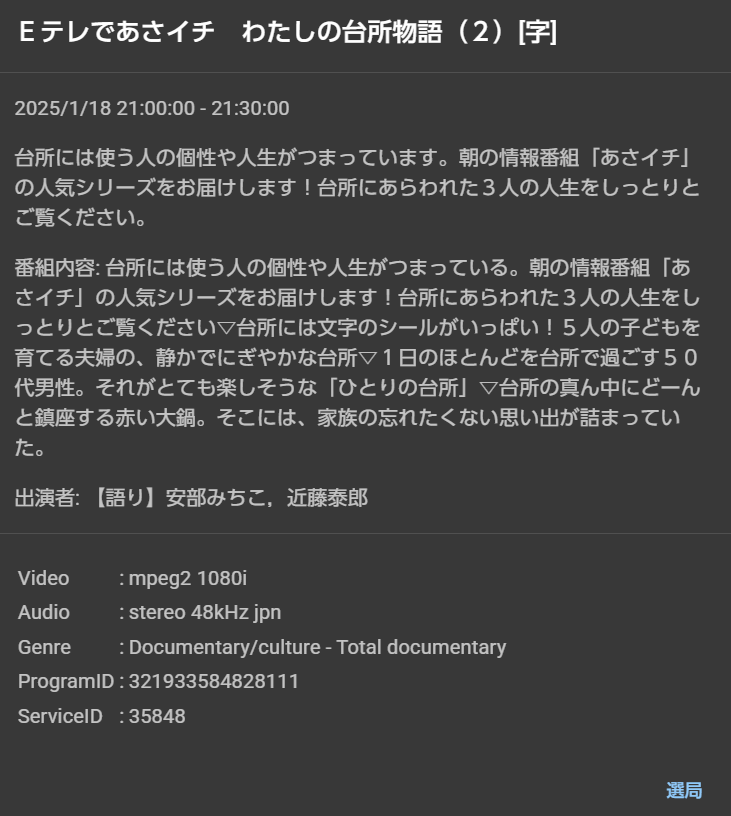
miraviewで番組を選ぶと、下記のように、ProgramIDが分かるのでこれをコマンドで予約追加する。ちなみに、選局のところでリンクされているURLをそのままmpvにD&Dすると再生できるのでリアルタイムに見たい場合はその形で見ている。
Rock5B上で、http://localhost:40772でmirakcにアクセスできる場合は、特に手間はないので、recording.shをダウンロードしてくればそのまま利用できる。
$ ./recording.sh add 321943585633026こうすると、/mnt/recording/mirakcに時間+ProgramIDの形でm2tsが生成されるので、これをAmatsukazeに食わせるところを次は用意していく。
Amatsukaze
CMカットとエンコードのためにAmatsukazeを経由して、NASにコピーする部分を構築していく。(NASは別に動いてるlinuxでjuicefsでiDrive e2をマウントしてて、sambaでアクセスできる前提)
AmatsukazeはWindowsで動かすので、Rock 5Bではなく、Windows 11が動いているN100のミニPCでやっていく。1.5万円くらいのやつ。N100なので、さすがに非力かなと思ったが、HEVCへのエンコードを試した感じ、速くはないが、そんなに大量に録画するわけでもなく、QSVを使えばそんなにひどい感じでもなかったのでN100で運用してみる。
Amatsukaze自体は、rigaya改造版Amatsukazeにする。N100にする前はRyzenのAPUが載ったPCで試していたので、VCEEncが使えるこちらを選んだだけで特に意味がないが、いろいろとメンテされていそうなので基本的にこちらを使うのが良さそう。
QSVEncCは別に持ってくる必要があるので、Githubから持ってきておく。
Amatsukazeを起動後、QSVEncCのパスなどを指定、プロファイルはQSVを使用するように変えて、エンコーダーのオプションは下記のようにした。
-c hevc --vpp-deinterlace bob --output-res 1920x1080 --la-icq 30 --gop-len 90ドラマとかをFireTVで再生する分にはこれで主観的にはまあ充分かなというところで適当に。
その他は局ロゴ消しの設定などを公式ドキュメント通りに設定していけば一旦設定は終了。
次はmirakcで録画したものを定期的にAmatsukazeのキューに積んでいく部分を整備する。
録画後の自動エンコード
ざっくりとした流れは、
- /api/recording/recordsを呼んで、finishedな番組を探す
- finishedな番組のtsを、分かりやすい番組名にリネームする
- AmatsukazeAddTask.exeを呼んでエンコードキューに積む
とすればとりあえず良いはず。
Rock5Bで呼びだそうかとも思ったが、AmatsukazeAddTask.exeをmonoで呼ぶなどするよりは、Windows側からmirakcのAPIを呼んでしまって、samba経由でファイルを扱ったほうが楽そうなので、ポーリングするスクリプトはWindows側で動かす。
# -*- coding: utf-8 -*-
import requests
import time
import os
import re
import shutil
import subprocess
import datetime
MIRAKC_API_URL = 'http://192.168.99.37:40772'
_invalid = (
34, # " QUOTATION MARK
60, # < LESS-THAN SIGN
62, # > GREATER-THAN SIGN
124, # | VERTICAL LINE
0, 1, 2, 3, 4, 5, 6, 7,
8, 9, 10, 11, 12, 13, 14, 15,
16, 17, 18, 19, 20, 21, 22, 23,
24, 25, 26, 27, 28, 29, 30, 31,
32, # SPACE
39, # ' APOSTROPHE
58, # : COLON
42, # * ASTERISK
63, # ? QUESTION MARK
91, # [ LEFT SQUARE BRACKET
93, # ] RIGHT SQUARE BRACKET
92, # \ REVERSE SOLIDUS
47, # / SOLIDUS
0x3000, # IDEOGRAPHIC SPACE
0x25bd, # WHITE DOWN-POINTING TRIANGLE
)
table1 = {}
for i in _invalid:
table1[i] = 95 # LOW LINE _
table2 = dict(table1)
table2.update((
(34, 0x201d), # ”
(60, 0xff1c), # <
(62, 0xff1e), # >
(124, 0xff5c), # |
(58, 0xff1a), # :
(42, 0xff0a), # *
(63, 0xff1f), # ?
(92, 0xffe5), # ¥
(47, 0xff0f), # /
(95, 0x301c), # 〜
))
def safefilenames(names, table=table1, add_table=None):
if add_table is None:
m = table
else:
m = dict(table)
m.update(add_table)
for name in names:
yield name.translate(m)
def safefilename(name, table=table1, add_table=None):
return next(safefilenames([name], table, add_table))
def remove_schedule(program_id):
try:
r = requests.delete("{0}/api/recording/schedules/{1}".format(MIRAKC_API_URL, program_id))
r.raise_for_status()
# r = requests.delete("{0}/api/recording/records/{1}".format(MIRAKC_API_URL, program_id))
# r.raise_for_status()
except requests.exceptions.RequestException as e:
print(e)
return False
def remove_record(program_id):
r = requests.get(f"{MIRAKC_API_URL}/api/recording/records")
try:
r.raise_for_status()
for record in r.json():
if record.get('program').get('id') == program_id:
try:
r = requests.delete("{0}/api/recording/records/{1}".format(MIRAKC_API_URL, record.get('id')))
r.raise_for_status()
except requests.exceptions.RequestException as e:
print(e)
return False
except requests.exceptions.RequestException as e:
print(e)
return False
return True
response = requests.get("{0}/api/recording/schedules".format(MIRAKC_API_URL))
for record in response.json():
record_status = record.get('state')
content_path = record.get('options').get('contentPath')
try:
start_at = datetime.datetime.fromtimestamp(int(record.get('program').get('startAt')) / 1000)
except:
start_at = datetime.datetime.now()
program_id = record.get('program').get('id')
program_name = record.get('program').get('name')
program_name = re.sub(r'\[.\]', '', program_name)
program_name = safefilename(program_name)
if len(program_name) > 128:
program_name = program_name[:127]
program_name = f"{start_at.strftime("%d_%H%M")}_{program_name}"
if record_status == 'finished':
print("name: {0}, path: {1}".format(program_name, content_path))
src_path = "N:\\mirakc\\{0}".format(content_path)
dst_path = "N:\\TS\\{0}.ts".format(program_name)
print("copy from {0} to {1}".format(src_path, dst_path))
try:
shutil.copy2(src_path, dst_path)
except FileNotFoundError:
print("File not found: {0}".format(src_path))
remove_schedule(program_id)
continue
subprocess.run(['..\\scripts\\add.bat', dst_path])
time.sleep(5)
remove_schedule(program_id)
remove_record(program_id)
try:
os.remove(src_path)
except FileNotFoundError:
print("File not found: {0}".format(src_path))
print("removed {0}".format(src_path))
elif record_status == 'failed':
print("Remove failed record on mirakc: {0}".format(program_name))
remove_schedule(program_id)
remove_record(program_id)
めちゃくちゃ雑だが、とりあえず、これをWindowsで実行すると、Amatsukazeでエンコードが始まる。
Amatsukaze側の実行後バッチでは、エンコードされたファイルをNASに移動する。
@echo off
rem 年
set sYear=%DATE:~0,4%
rem 月(ゼロ埋め対応)
set sMonth=0%DATE:~5,2%
set sMonth=%sMonth:~-2,2%
rem 年月(YYYYMM)
set sYYYYMM=%sYear%%sMonth%
mkdir "J:\%sYYYYMM%"
mkdir "J:\%sYYYYMM%\%SERVICE_ID%_%SERVICE_NAME%"
for /f "delims=" %%a in ('GetOutFiles v') do (
copy /B "%%a" "J:\%sYYYYMM%\%SERVICE_ID%_%SERVICE_NAME%"
)
if %SUCCESS% equ 1 del "%IN_PATH%" "%IN_PATH%.err" "%IN_PATH%.program.txt"
for /f "delims=" %%i in ("%IN_PATH%") do set IN_DIR=%%~dpi
echo "%IN_DIR%" 1>&2
rd "%IN_DIR%..\succeeded"
rd "%IN_DIR%..\failed"こちらも同じように雑だが、J:にNASをマウントしていて、エンコードされたファイルをそちらに、年月のディレクトリを作り、その下に放送局毎にさらにディレクトリをつくって、エンコード後のmp4をコピーする。その後、m2tsはすべて削除する、という形にした。
一番のはまりどころは、GetOutFilesがダウンロードしてきたzipを展開したやつだとどうも実行を許可されていない状況になるようで、exe_files以下のDLLのプロパティを開いて、実行許可をするみたいなことが必要だった、まとめてやる方法がわからなくて各ファイルでやるのが地味に面倒。
これでとりあえず、録画後にPythonスクリプトを叩けばAmatsukazeを経由して、NASにエンコード後のファイルが配置される。これを定期的に実行すればよいか、と思っていたが、この後、キーワード予約を作るとすると、mirakcのSSEイベントでEPG更新時に検索をかけるという処理をずっとするプロセスを作るのであれば、録画終わりのイベントもそこで取るのがよいかなぁということで、次はSSEを受信して、任意のコマンドを実行するようなやつを作る。
# -*- coding: utf-8 -*-
import traceback
import json
import asyncio
import aiohttp
from aiohttp_sse_client import client as sse_client
MIRAKC_API_URL = 'http://192.168.99.37:40772'
queue = asyncio.Queue()
async def job_loop():
while True:
try:
print("waiting for job...")
job = await queue.get()
if job is None:
break
await exec_command(job)
queue.task_done()
except Exception as e:
traceback.print_exc()
async def exec_command(cmd):
print(f"exec: {cmd}")
p = await asyncio.create_subprocess_shell(cmd)
await p.wait()
async def sse_request():
event_count = 0
session = aiohttp.ClientSession(timeout=aiohttp.ClientTimeout(total=60 * 60 * 12))
async with sse_client.EventSource(
url=f'{MIRAKC_API_URL}/events',
session = session
) as event_source:
try:
async for event in event_source:
event_count += 1
if event_count < 100:
continue
match event.message:
case 'epg.programs-updated':
event_data = json.loads(event.data)
print(f"search keyword in channel => {event_data['serviceId']}")
await queue.put(f"uv run searchPrograms.py keywords.yml {event_data['serviceId']}")
case 'recording.record-saved':
event_data = json.loads(event.data)
recording_status = event_data['recordingStatus']
if recording_status == 'finished':
print("recording saved", recording_status)
await queue.put("uv run checkAndAddTask.py")
except TimeoutError as e:
print("timeout error: ", e)
await event_source.close()
await session.close()
async def sse_loop():
while True:
try:
print("try sse request...")
await sse_request()
except Exception as e:
traceback.print_exc()
async def start_app():
sse_task = asyncio.create_task(sse_loop())
job_task = asyncio.create_task(job_loop())
await asyncio.gather(sse_task, job_task)
if __name__ == '__main__':
asyncio.run(start_app())
2025/02 asyncio使うものに書換。こちらのほうが見通しが良さそうだったので。
こちらも雑にSSEで受信し続けて、programs-updatedではキーワード予約コマンド、recording.stoppedでは録画一覧を取って、finishedになっているものをAmatsukazeつっこむコマンドをそれぞれ起動する。
mirakcは接続時に、epg.programs-updatedをチャンネル数xチューナ数分?送ってくるようで、単純にsubprocess.Popenなどで起動すると20並列とかでプロセスが作られてしまうので、キューにして順次実行にする。
ちなみに、これだとEPG更新ごとに同じ番組を予約しようとするので、400が返ってくるがまあ無視すれば問題なかろうということで、すでに予約があるかどうか等はチェックしていない。
キーワード予約は下記のようなスクリプト
# -*- coding: utf-8 -*-
import requests
import datetime
MIRAKC_API_URL = 'http://192.168.99.12:40772'
def search_programs(word, desc=None, searviceId=None):
url = f"{MIRAKC_API_URL}/api/programs"
if searviceId is not None:
url = f"{MIRAKC_API_URL}/api/services/{searviceId}/programs"
response = requests.get(url)
response.raise_for_status()
programs = response.json()
matched_programs = []
for program in programs:
name = program.get('name')
if name is None:
continue
if word in name:
matched_programs.append(program)
elif desc is not None:
description = program.get('description')
if description is None:
continue
if desc in description:
matched_programs.append(program)
return matched_programs
def add_program_to_schedule(program_id, content_path):
url = f"{MIRAKC_API_URL}/api/recording/schedules"
payload = {
"programId": program_id,
"options": { "contentPath": content_path },
"tags": ["auto-search"]
}
# print(payload)
response = requests.post(url, json=payload)
response.raise_for_status()
return response.json()
if __name__ == '__main__':
import sys
import yaml
with open(sys.argv[1], encoding="utf-8") as f:
keywords = yaml.safe_load(f)
for keyword in keywords:
serviceId = keyword.get('serviceId')
word = keyword.get('name')
desc = keyword.get('desc')
for program in search_programs(word, desc, serviceId):
pid = program.get('id')
name = program.get('name')
try:
start_at = datetime.datetime.fromtimestamp(int(program.get('startAt')) / 1000)
except:
print("startAt is invalid, skip: name: {0}".format(name))
continue
if start_at < datetime.datetime.now():
print("program already has been ended, skip: name: {0}, startAt: {1}, now: {2}".format(name, start_at, datetime.datetime.now()))
continue
content_path = "{0}_{1}.m2ts".format(start_at.strftime("%Y%m%d%H%M"), pid)
# print(f"ProgramID: {pid}, Name: {name}, StartAt: {start_at}, contentPath: {content_path}")
try:
result = add_program_to_schedule(pid, content_path)
print(f"Added to schedule: {result.get('status')}, {result.get('name')}")
except requests.exceptions.HTTPError as e:
# print(e)
pass
mirakc/contribにある、mirakc-searchとかでシェルスクリプトで書こうかとおもったが、設定ファイルを読む部分とかはスクリプト書いた方が速そうだったので、まるっとpythonで。
キーワードは単純なリストで、name, desc, serviceIdの3つだけ指定できる。
- name: "ミステリ"
# - serviceId: 35848 # "NHKEテレ1静岡"
# - name: "買物"
# - desc: "買物"これでeventrecv.pyを起動しておけば勝手に予約が追加され、録画が終わるとAmatsukaze経由で、NASに録画が貯まる。
JuiceFS
あとはNASをどうするか、というところだが、自宅では基本的にs3backer+iDrive e2の組み合わせで、S3互換のストレージサービスをNASとして利用しているんだけど、どっかで見かけたjuicefsが割と良さそうだったので、今回はこの録画システム用にjuicefsでmountしたものをsambaで利用する。
JuiceFSはメタデータとストレージをそれぞれ組み合わせてファイルシステムとしてマウントできるので、今回は、メタデータはSQLite+ストレージはS3互換のiDrive e2を安いので利用する。
フォーマット&マウントするまでは公式ドキュメント通りで問題なし。
# default installation path is /usr/local/bin
# curl -sSL https://d.juicefs.com/install | sh -
# juicefs format sqlite3://myjfs.db myjfs
# sudo juicefs mount --enable-xattr --cache-dir=/mnt/cache/juicefscache --cache-size=5000 sqlite3://myjfs.db /mnt/myjfs上記のような感じで、/mnt/myjfsにマウントする。
10TBのHDDをつないでいるので、5TB分のキャッシュを指定する。それなりに速いPCと回線は必要ではあるが、DLNAで再生したときに詰まったりするようなことはなさそう。
ただ、メタデータがローカルファイルになってこれが壊れると泣いてしまうので、こちらはlitestreamを使ってS3にバックアップしておく。
litestreamのパッケージをもってきて入れておけば、/etc/litestream.ymlに書いておけばあとは勝手にレプリケーションがはじまる。
# systemctl enable litestream
# systemctl start litestreamは要るかもしれない。
dbs:
- path: /mnt/cache/juicefs/myjfs.db
replicas:
- type: s3
endpoint: https://xxxx.la.idrivee2-31.com
bucket: xxxx
forcePathStyle: false
access-key-id: xxxxxxxxxxx
secret-access-key: yyyyyyyyyyyyyyyyyyyyyyy
sync-interval: 30smyjfs.dbもiDrive e2にレプリケーションしておくことで、ファイルが壊れたり、HDDがクラッシュした場合はそこから持ってくれば復元できるはず。(試してないけど)
ここまでくると、あとは、sambaで/mnt/myjfsをAmatsukazeがうごいているPCから参照できるように設定追加して起動しておく。
[myjfs]
comment = myjfs
path = /mnt/myjfs
public = yes
writable = yes
read only = no
guest ok = yesあとは、動画ファイルを再生するときは、自宅ではFireTV CubeにDiXiMを入れてDLNAで再生するので、rcloneでサーバを起動しておく。
$ rclone serve dlna /mnt/jfs手元の環境では、N:がRock5Bでmirakcが動いている、J:にNASが動いているという状態で、上記のスクリプトを動かしていればFireTV Cubeから録画番組が再生できるようになっているはず。
終わりに
長々と構築手順を書いたが、まあ、正直、これだけ全部再現する人は居ないよなと書いてから思ったが、自分のための備忘録として置いておく。
あとはBSもアニメのために録画できるようにしたいので、チューナーは足そうかなと思っているのと、N100でAmatsukazeを動かすのはやはりすこしキツイかなという気がしてきたので、Ryzen 7840HSくらいのミニPCを導入して、今のN100のほうをmirakcを動かすのに使う形に構成を変えたほうがいい気はしてきている。
とはいえ、3日くらいはこれにかかりきりになったので、しばらくはこのまま様子見かな……